

Эта история началась с банальной усталости — мне надоело каждую неделю совершать одни и те же монотонные действия. Я мечтал об инструменте, который бы самостоятельно следил за папкой, извлекал данные из PDF-файлов, обогащал их, формировал отчёты и, в идеале, выставлял кому-нибудь счёт за сэкономленное время. Пару выходных, несколько библиотек и множество чашек кофе спустя у меня появился продукт, за который люди были готовы платить.
Ниже я подробно расскажу, какой стек я использовал, как выстроил архитектуру, какие шаги предпринял для монетизации и какие паттерны кода применил. Вы увидите практические примеры, структуру на основе объектно-ориентированного программирования и даже одну маленькую хитрость с C++, которая выручила там, где чистый Python оказался слишком медленным.
1. Проблема, которую я решил (и почему стоит браться за маленькие, но наболевшие задачи)
Большинство проектов по автоматизации проваливаются, потому что их авторы пытаются объять необъятное. Вместо этого выберите одну повторяющуюся, болезненную задачу с измеримой отдачей. В моём случае она выглядела так:
- Клиент ежедневно присылает счета в виде разрозненных PDF-файлов.
- Я вручную открываю каждый, копирую название поставщика, дату, сумму и вставляю всё это в Google-таблицу.
- Каждый день на это уходило около 20 минут драгоценного времени.
Цель: свести эти 20 минут ручного труда к нулю и предложить решение в качестве платной услуги.
2. Быстрый MVP: создаём наблюдатель за файлами и экстрактор PDF
Начинать нужно с малого: программа должна следить за папкой, обнаруживать новые PDF и извлекать из них текст. Для этого идеально подходят библиотеки watchdog и PyMuPDF (также известная как fitz).


Уже этот простой скрипт сократил мою ежедневную рутину до 5 минут, которые уходили в основном на проверку результатов.
3. Делаем экстрактор надёжнее: OCR как запасной вариант
Некоторые PDF — это, по сути, просто отсканированные изображения, и текста в них нет. На этот случай добавим распознавание с помощью pytesseract.

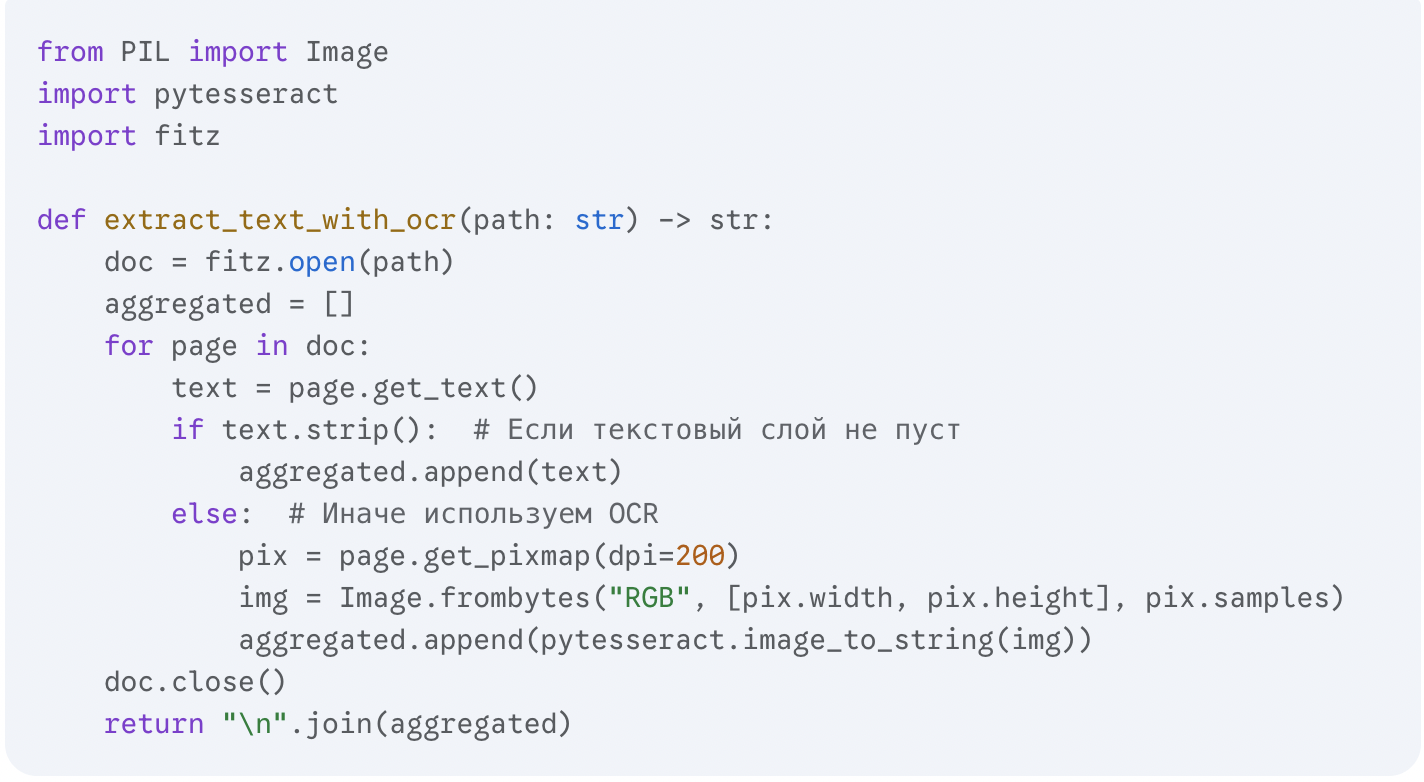
Такой гибридный подход (сначала текстовый слой, потом OCR) сделал инструмент надёжным для 95% счетов, с которыми я сталкивался.
4. Структурируем с помощью ООП: создаём конвейер с поддержкой плагинов
Если вы планируете превратить скрипт в продукт, его конвейер (pipeline) должен быть модульным. Каждый этап — это отдельный класс: Loader (загрузчик) → Parser (парсер) → Enricher (обогатитель) → Sink (приёмник). Это позволяет легко менять хранилище (с Google-таблиц на базу данных или webhook), не переписывая всю логику.

Этот паттерн легко масштабируется: можно добавить ClassifierStep для определения языка, TranslatorStep для документов на иностранных языках и так далее.
5. Извлечение и обогащение данных: от регулярных выражений к машинному обучению
Начинайте с детерминированного парсинга, то есть с регулярных выражений. Если счета имеют сложную или меняющуюся структуру, подключите модель машинного обучения (например, с помощью layout-parser). Вот пример простого регулярного выражения:

Для большей надёжности можно использовать spaCy с кастомной моделью NER (распознавание именованных сущностей) или layout-parser для определения полей счёта по их расположению.
6. Веб-автоматизация: используем Playwright для загрузки файлов
Когда счета-фактуры спрятаны за логином и паролем на веб-порталах, их загрузку можно автоматизировать с помощью Playwright.

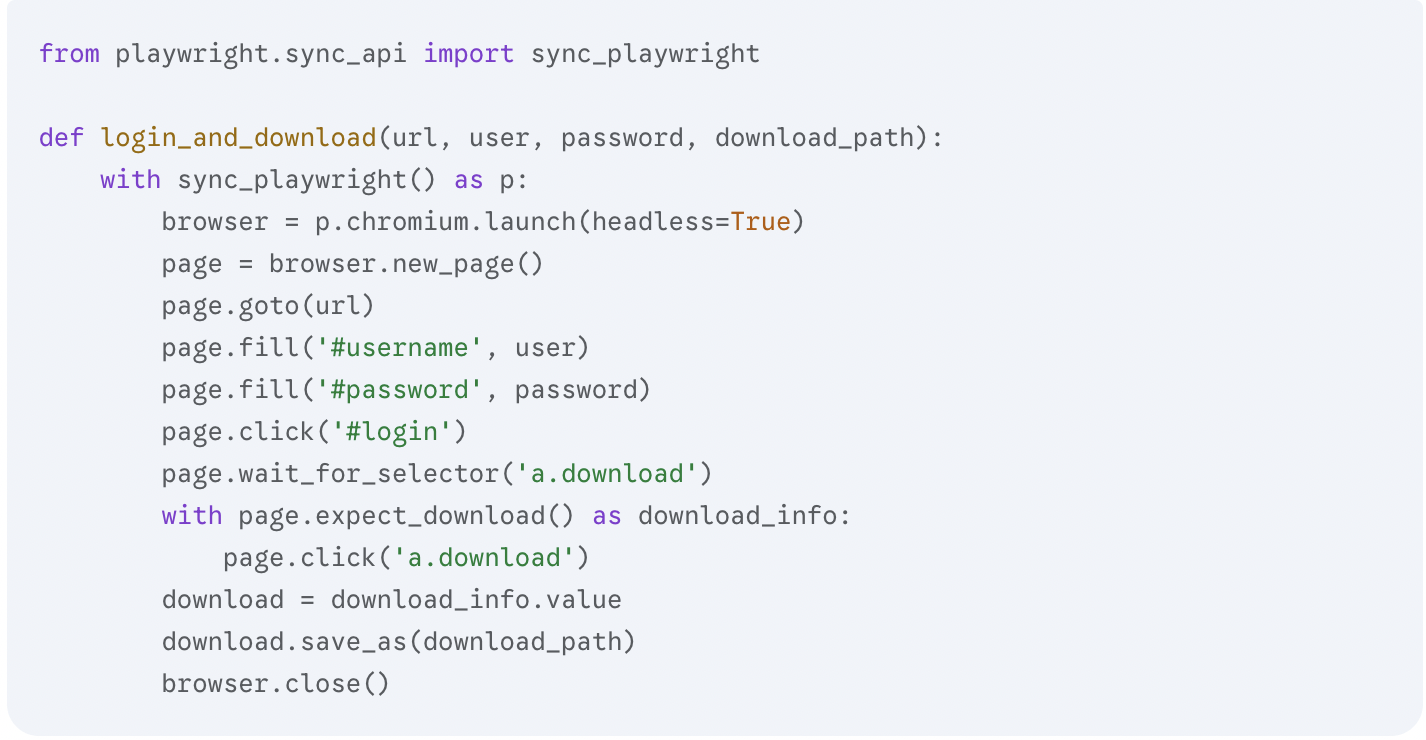
Это позволяет вашему сервису самостоятельно забирать исходные PDF-файлы, что крайне важно, если вы хотите продавать подписку, по которой система каждое утро сама собирает документы клиентов.
7. Упаковка инструмента: создаём CLI с помощью Typer или Click
Чтобы инструментом было удобно пользоваться (как вам на сервере, так и клиентам локально), оберните его функциональность в интерфейс командной строки (CLI).


Создайте файл setup.py или pyproject.toml и опубликуйте пакет на PyPI, либо упакуйте его в wheel-файл или Docker-образ.
8. Когда Python слишком медленный: ускоряемся с C++ (pybind11) или Cython
Для тяжёлой обработки изображений или массового предварительного анализа для OCR, Python может стать узким местом. У меня был один такой шаг (кастомное преобразование изображений), который нужно было выполнять для тысяч страниц в день. Я переписал его на C++ и подключил к Python через pybind11.
Схема подхода:
- Написать «тяжёлую» функцию на C++.
- Обернуть её с помощью
pybind11. - Импортировать скомпилированный модуль в Python как обычную библиотеку.
Этот небольшой рефакторинг сократил время выполнения этого шага с ~120 мс до ~10 мс на страницу.
9. Масштабирование с помощью воркеров: Celery + Redis
Когда пользовательская база растёт, запускайте обработку в фоновых очередях задач, чтобы не блокировать основной процесс.


Теперь ваш веб-интерфейс или API может просто ставить задачу в очередь process_file.delay(path) и мгновенно отвечать пользователю, пока воркеры в фоне делают всю работу.
10. Наблюдаемость и надёжность: логи, метрики и отказоустойчивость
Используйте loguru для структурированного логирования и экспортируйте метрики (например, с помощью Prometheus) для отслеживания времени безотказной работы, длины очередей и частоты сбоев.


Проектируйте шаги вашего конвейера так, чтобы они были идемпотентными и поддерживали повторные попытки. Это гарантирует, что случайный сбой не приведёт к дублированию данных.
11. Стратегии монетизации: от фриланса до SaaS-сервиса
Как я превратил это в деньги:
- Фриланс-заказы (первые деньги): Я предложил нескольким местным компаниям автоматизировать обработку их счетов. Это принесло быстрый доход при минимальных затратах на поддержку.
- Оплата за документ: Взимание платы за каждый обработанный счёт (например, $0.10–$0.50) — отличный вариант для клиентов с большими объёмами.
- Ежемесячная подписка: Вы размещаете сервис у себя, настраиваете сбор данных (через Playwright или SFTP) и берёте плату за удобство и гарантированный уровень обслуживания (SLA).
- White-label / Enterprise: Интеграция с бухгалтерскими платформами; взимается плата за настройку и ежемесячная лицензия.
- Продажа шаблонов: Продажа обученных парсеров или шаблонов (например, «Парсер для счетов-фактур формата X») как разовых покупок.
Ключевые тактики, которые помогли мне привлекать клиентов:
- Двухнедельный бесплатный пробный период (обработка первых 50 счетов бесплатно).
- Прозрачный отчёт о точности (сравнение результатов парсинга с ручным вводом).
- Предложение услуги «human-in-the-loop» — ручная проверка для документов, в которых система не уверена (дополнительный источник дохода).
Приложение — минимальный скелет репозитория
Используйте эту структуру как основу для вашего проекта.

✨ А что думаете вы? ✨
Делитесь мыслями в комментариях — ваше мнение вдохновляет нас и других!
Следите за новыми идеями и присоединяйтесь:
• Наш сайт — всё самое важное в одном месте
• Дзен — свежие статьи каждый день
• Телеграм — быстрые обновления и анонсы
• ВКонтакте — будьте в центре обсуждений
• Одноклассники — делитесь с близкими
Ваш отклик помогает нам создавать больше полезного контента. Спасибо, что вы с нами — давайте расти вместе! 🙌