
Один из самых популярных способов присвоить каждой строке в базе данных уникальный идентификатор — использовать UUID. Казалось бы, это удобно: никакого риска дублирования, можно создавать записи параллельно, не заботясь об уникальности. Но за эту универсальность приходится платить. Причём не просто удобством, а скоростью и объёмом.
В этой статье мы разберём два скрытых недостатка UUID — те, что напрямую влияют на производительность SQL-баз данных. Если вы проектируете масштабируемую систему, эти нюансы могут в определённый момент стать критичными.
Так что без лишних вступлений — ныряем вглубь проблемы.
Что такое UUID?
UUID расшифровывается как Universally Unique Identifier — универсальный уникальный идентификатор. Это строка длиной 128 бит, способная описать уникальный объект без участия централизованной системы. В статье мы сосредоточимся на версии 4 (UUIDv4), самой распространённой и интуитивной.
Вот как выглядит типичный UUIDv4:
f47ac10b-58cc-4372-a567-0e02b2c3d479
Обратите внимание: в каждом таком идентификаторе 13-й символ всегда будет «4» — это и есть обозначение версии.
Проблема №1 — Медленные вставки (Insert Performance)
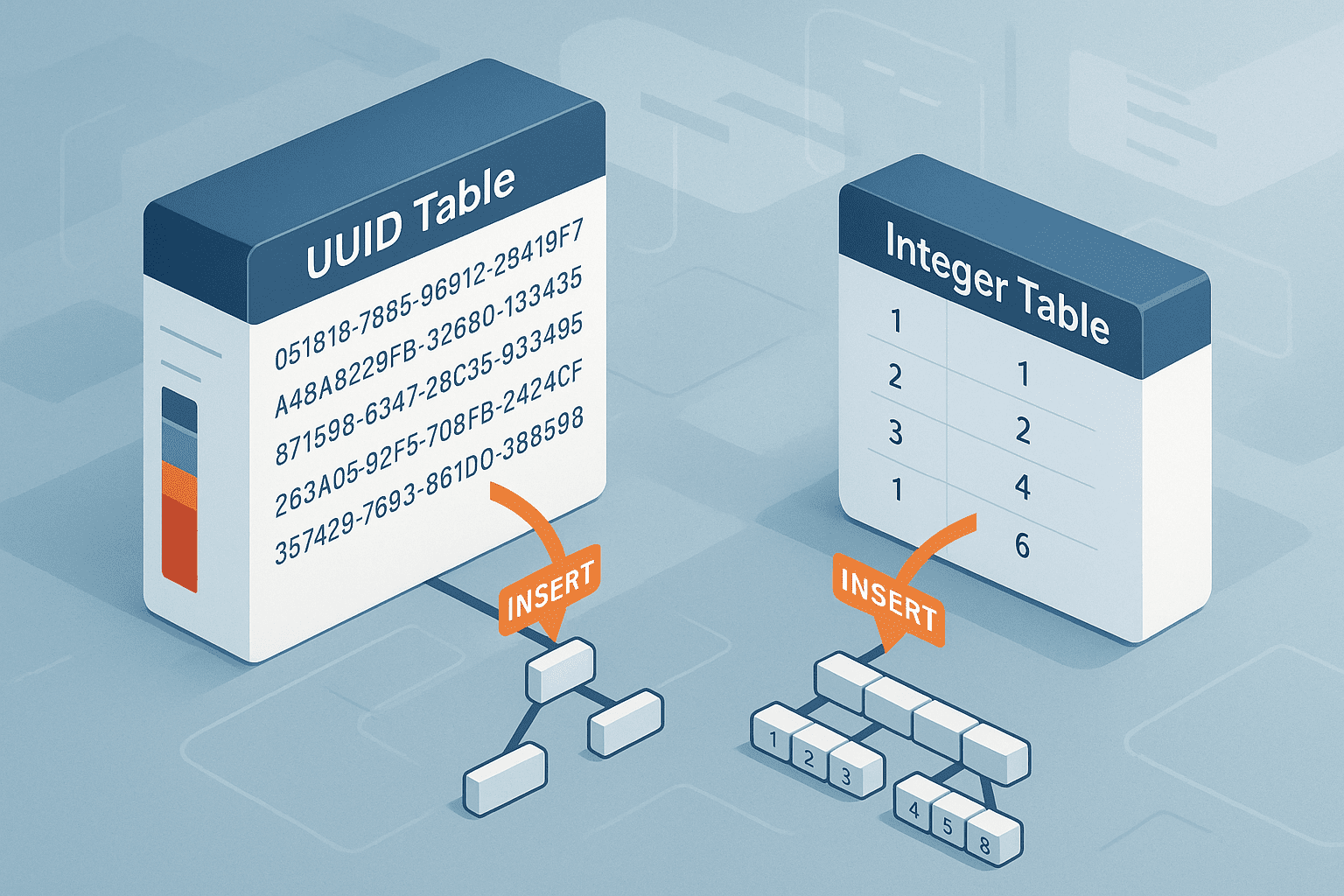
Каждый раз, когда в таблицу добавляется новая запись, база данных должна обновить индекс первичного ключа, чтобы сохранить быструю выборку по этому ключу. Индексы в большинстве SQL-баз данных (включая PostgreSQL и MySQL) строятся на основе структуры данных B+-дерево.
И вот здесь начинаются трудности: UUID, особенно версии 4, создаются случайным образом. А это означает, что каждая новая запись скорее всего попадёт в произвольное место дерева. Иными словами, оно будет всё время «разбалансировано».
Для B+-дерева такая разбалансировка оборачивается постоянной необходимостью перестраиваться — то есть тратить ресурсы на поддержание равновесия. Чем больше записей, тем сложнее становится эта задача. Если вы оперируете миллионами строк, то UUID превращаются в настоящую катастрофу для insert-производительности.
Для сравнения: автоинкрементные ID растут последовательно, что позволяет дереву расти линейно и упорядоченно — без серьёзных затрат на балансировку.
💡 Примечание: UUIDv7 решает эту проблему частично, так как его структура частично основана на времени и упорядочена по возрастанию.
Проблема №2 — Избыточное потребление памяти
Может показаться, что увеличение на 128 бит — это сущая мелочь. Но теперь сравните: обычный целочисленный ID занимает 32 бита, а UUID — 128 бит. В четыре раза больше на одну строку.
Но на практике всё ещё хуже.
Большинство разработчиков хранят UUID не в бинарном, а в строковом (читаемом) формате. А это — уже 36 символов, каждый из которых занимает не менее 1 байта (а часто и 2 байта в зависимости от кодировки). В результате одна запись с UUID может потреблять до 688 бит — это примерно в 20 раз больше, чем целочисленный ID.
Когда у вас десятки или сотни миллионов записей — такой объём начинает превращаться в заметную нагрузку на дисковое пространство и кэш базы данных.
Эмпирическая проверка: UUID против автоинкремента
Чтобы оценить реальные последствия использования UUID, автор статьи смоделировал два варианта таблиц:
- Таблица 1: 1 миллион строк с UUID.
- Таблица 2: 1 миллион строк с автоинкрементными целыми числами.
База данных — PostgreSQL, размещённая на платформе Neon.
Результаты:
- Общий размер таблицы с UUID оказался в 2.3 раза больше, чем таблицы с int.
- Один только UUID-поле ID весит в 9.3 раза больше, чем int.
- Если исключить остальные поля и оставить только ID-колонку — UUID занимает в 3.5 раза больше места.
Почему это всё важно?
Да, UUID действительно удобны. Они хороши для распределённых систем, для взаимодействия между сервисами, где централизованный контроль ID невозможен. Но если говорить о локальной реляционной базе, особенно в контексте высокой нагрузки — такой подход может сыграть злую шутку.
Медленные вставки и раздутый размер базы — это реальность, если вы используете UUIDv4 не по назначению.
Конечно, для небольших проектов эти проблемы незаметны. Но если вы строите систему с прицелом на масштаб, выбор первичного ключа — это не просто вкусовщина. Это — вопрос архитектуры и эффективности.
Заключение
UUID — это мощный инструмент. Но, как и любой инструмент, он должен применяться там, где это действительно необходимо. Иначе он превращается в лишнюю нагрузку на систему.
Если вы всё же выбираете UUID, задумайтесь о UUIDv7 или бинарном хранении. А если можно обойтись обычными автоинкрементными ключами — лучше так и поступить.
Базы данных не про элегантность — они про производительность. Не позволяйте модным решениям подорвать фундамент ваших систем.
***✨ А что думаете вы? ✨
Делитесь мыслями в комментариях — ваше мнение вдохновляет нас и других!
Следите за новыми идеями и присоединяйтесь:
• Наш сайт — всё самое важное в одном месте
• Дзен — свежие статьи каждый день
• Телеграм — быстрые обновления и анонсы
• ВКонтакте — будьте в центре обсуждений
• Одноклассники — делитесь с близкими
Ваш отклик помогает нам создавать больше полезного контента. Спасибо, что вы с нами — давайте расти вместе! 🙌