
Галлюцинации искусственного интеллекта — словосочетание, которое у всех на слуху. Кажется, что мы интуитивно понимаем, о чем речь, но в действительности это явление куда глубже и сложнее, чем кажется на первый взгляд. Большинство из нас сталкивалось с моментами, когда чат-бот уверенно выдавал полную чушь, и мы лишь пожимали плечами.
Но что, если я скажу вам, что теперь эти галлюцинации можно буквально увидеть в реальном времени? Новое исследование позволяет не просто зафиксировать ошибку постфактум, а наблюдать за её рождением в «сознании» нейросети. Это открытие не только проливает свет на внутреннюю кухню генеративного ИИ, но и даёт нам ключ к решению одной из самых насущных проблем этой технологии.
Давайте же разберёмся, что такое галлюцинации на самом деле, посмотрим на них «своими глазами» и узнаем о новых, захватывающих способах их предотвращения.
Что это вообще такое?
Начнём с того, что сам термин «галлюцинация» сбивает с толку. Если задуматься, то можно с уверенностью сказать, что генеративные модели по своей природе галлюцинируют постоянно. Ведь вся их работа — это непрерывный процесс генерации чего-то нового на основе вероятностей.
Действительно ли ИИ галлюцинирует, только когда ошибается?
Можно утверждать, что каждый ответ нейросети — это своего рода галлюцинация, и вот почему:
- Неясно, понимает ли модель то, что говорит. Особенно это касается так называемых «неявных знаний» — того, что сложно выразить словами (например, здравый смысл или культурный контекст). Вполне возможно, что ИИ просто искусно имитирует понимание, «галлюцинируя» осмысленные на вид тексты.
- Каждый ответ стохастичен. Это означает, что в процессе генерации всегда присутствует элемент случайности. Он проявляется как на уровне софта (следующее слово выбирается из нескольких вероятных вариантов, а не строго по одному алгоритму), так и на уровне «железа». Из-за особенностей распределённых вычислений на тысячах ядер GPU математические операции могут выполняться в разном порядке, что приводит к микроскопическим ошибкам округления. В результате, как бы невероятно это ни звучало, иногда
(a+b)+cне равно(a+c)+b, и это тоже вносит свою лепту в непредсказуемость ответа.
Многие эксперты утверждают, что более точным термином был бы «конфабуляция» — психиатрический термин, обозначающий создание ложных воспоминаний без намерения обмануть. Однако этот поезд уже ушёл, и слово «галлюцинация» прочно вошло в обиход.
Впрочем, когда большинство людей говорят о галлюцинациях, они имеют в виду конкретную вещь: генерацию правдоподобно звучащего, но фактически неверного контента.
Именно на этом определении и сосредоточилась группа исследователей из Швейцарской высшей технической школы Цюриха (ETH Zurich). Они создали поразительно эффективный «детектор галлюцинаций», который, в отличие от предыдущих разработок, не просто выявляет ошибки в готовом тексте, а сигнализирует о них прямо в процессе генерации ответа. Это позволяет вмешаться и остановить нейросеть до того, как её «занесёт» окончательно.
Как это вообще возможно? Ответ кроется не в магии, хотя и очень на неё похож. Технология основана на анализе латентного пространства модели. Давайте разберёмся, что это такое.
Заглянем внутрь «сознания» ИИ
Когда нейросеть обучается, она формирует внутреннее, математическое представление о мире. Все понятия, которые она «знает», она организует в едином, многомерном пространстве, которое называется латентным. Звучит заумно, но на деле всё просто.
Представьте, что мы говорим только о животных. Модель может классифицировать их по разным признакам. Например, понятие «кошка» будет находиться очень близко к «собаке» или «тигру». Все они вместе образуют кластер «животные», а внутри него — подкластер «млекопитающие». Модель не знает, что такое млекопитающее в биологическом смысле, но она видит, что «кошка» по своим текстовым признакам очень похожа на другие понятия, которые тоже являются «млекопитающими», и делает соответствующий вывод.
Поскольку у моделей нет возможности соотнести понятия с реальным миром (те самые неявные знания), они познают мир через сходства и различия: насколько один объект похож на другие известные ей объекты.
Взгляните на изображение ниже.
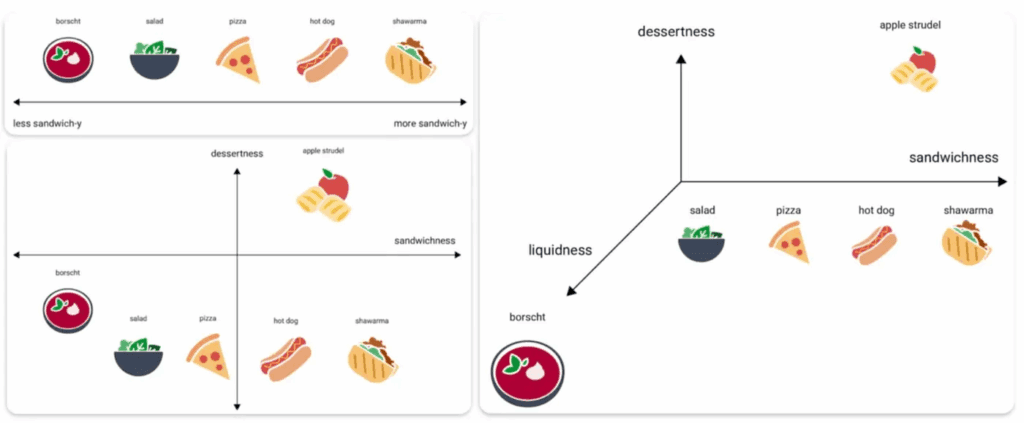
Здесь мы видим пример с разными блюдами: борщ, салат, пицца, хот-дог, шаурма и яблочный штрудель. Мы можем классифицировать их по разным «осям» или «направлениям».
- Если мы используем только один признак — «сэндвичность» (насколько блюдо похоже на сэндвич), — мы получим одномерную шкалу.
- Если добавим «десертность», получится уже двумерная плоскость.
- А если добавить «жидкостность», мы получим трёхмерную карту понятий.
С каждым новым признаком (измерением) наша карта становится всё более детальной и точной.
Со временем, добавляя тысячи таких измерений, можно построить невероятно богатые карты понятий, например, карту человеческих эмоций, выраженных голосом.
Самое интересное, что предыдущие исследования в области «механистической интерпретируемости» (науки о том, как заглянуть в чёрный ящик нейросетей) показали, что этими измерениями могут быть не только физические атрибуты. Модели также оперируют такими абстрактными понятиями, как «достоверность», «уверенность» или «фактологичность».
То есть, по причинам, которые мы пока не до конца понимаем, модель, кажется, кодирует степень своей уверенности в каждом понятии. Проще говоря, нейросети неявно измеряют уровень «истинности» или «ложности» своих собственных убеждений.
Важно понимать: я не говорю, что модели знают истину или стремятся к ней. Я говорю о том, что они, похоже, оценивают вероятность истинности своих знаний на основе… назовём это «внутренними убеждениями». Они кодируют неуверенность в своих собственных предположениях. Иначе говоря, они могут оценить, насколько вероятно, что их убеждение «Оттава — столица Канады» является верным.
И поскольку это латентное пространство является векторным, то есть все расстояния и направления в нём математически измеримы, это означает нечто невероятное: мы можем математически предсказывать галлюцинации.
Предсказание ошибок в реальном времени
Подход исследователей заключается в использовании так называемого линейного зонда (linear probe). Это небольшая, простая модель ИИ, которая анализирует внутренние процессы (активации) основной, большой модели и предсказывает, собирается ли та сгенерировать галлюцинацию.
Чтобы понять, как это работает, вспомним базовый принцип работы больших языковых моделей (LLM). Когда вы отправляете запрос в ChatGPT, слова проходят через множество слоёв, где происходят две основные вещи:
- Смешивание внимания (Attention Mixing). Каждое слово «общается» с другими словами в контексте, чтобы лучше понять их смысл. Например, во фразе «Чёрный лес» слово «лес» обращает «внимание» на слово «Чёрный», и его внутреннее представление обогащается атрибутом чёрного цвета.
- Добавление знаний (Knowledge-adding). Помимо анализа контекста, модель добавляет и свои внутренние знания. Например, если речь идёт о компании «Black Forest Labs», модель может понять по заглавным буквам, что это не просто случайный чёрный лес, а название организации, и добавит к представлению слова «Forest» информацию, связанную с этой компанией.
Этот двухэтапный процесс повторяется много раз, слой за слоем, обогащая контекст. В конце концов, модель формирует единое, комплексное представление всего запроса, которое затем «декодируется» обратно в текст ответа.
Исследователи задались вопросом: «А что, если мы можем подсмотреть за этим внутренним процессом и определить, уверена ли модель в том, что собирается сказать?»
Прогнозирование неуверенности
Как мы выяснили, любое понятие можно «разложить» на множество направлений в латентном пространстве. Если одно из таких направлений — это «сэндвичность», то модель может оценить степень «сэндвичности» любого известного ей слова.
А что насчёт «достоверности» или «неуверенности»?
Модели также представляют и эти абстрактные признаки. Исследователи создали тот самый линейный зонд — небольшую модель, которая, по сути, проецирует любое текущее «размышление» большой модели на ось «достоверности/неуверенности».
Иными словами, этот «детектор галлюцинаций» в реальном времени проверяет, насколько «фактологичным» или, наоборот, «сомнительным» является то понятие, которое модель собирается сгенерировать в следующий момент.
И знаете что? Это работает!
В ходе различных тестов «предсказатель галлюцинаций» показал точность (метрика AUC) почти 0.9 (где 1.0 — идеальный результат). Это означает, что система с очень высокой вероятностью отличает истинную галлюцинацию от корректного ответа.
Проще говоря, детектор, обученный на тысячах примеров с чёткими метками «галлюцинация/не галлюцинация», выявил ключевые паттерны во внутреннем «мышлении» модели, которые обычно предшествуют реальным ошибкам.
Важно уточнить: детектор не знает всех фактов на свете. Он лишь внимательно следит за тем, как модель конструирует понятия в своём «внутреннем мире», и ищет признаки высокой «неуверенности».
Представьте себе полиграф. Он не знает, о чём именно лжёт человек, но фиксирует физиологические реакции, связанные с ложью. Так и здесь: зонд не знает правды, но измеряет, демонстрирует ли модель признаки «сомнения» перед тем, как выдать следующий токен.
Более того, зонд показал удивительные результаты:
- Способность к обобщению: он хорошо выявляет ошибки в математике, даже если его не обучали на математических задачах.
- Глобальные знания: он эффективно работает с общеизвестными фактами.
- Кросс-модельная совместимость: паттерны «неуверенности», найденные в одной модели, применимы и к другим моделям.
Так в чём же прорыв?
Уникальность этого подхода в том, что он позволяет мгновенно помечать потенциально неверные слова, визуализируя их в реальном времени.
Но что ещё важнее, эту технологию можно использовать для активного предотвращения генерации неверных ответов. Можно даже научить модель, получив такой сигнал, самостоятельно перепроверять свои утверждения.
Это исследование также помогает понять фундаментальную природу галлюцинаций. Иногда высокая неопределённость — это не ошибка. Если вы просите модель сочинить историю, и она начинает фразу с «Мне нравится…», то продолжения могут быть бесконечными («шоколад», «кошки», «дождь»). Неуверенность будет высокой в любом случае, но это не галлюцинация.
Однако в других случаях модель действительно сомневается в факте, у которого есть единственно верный ответ. И как только она совершает первую ошибку, она входит в «режим ошибок» и начинает галлюцинировать с удвоенной силой, потому что сама себя завела на неизвестную территорию.
Это называется накоплением ошибки. Допустив один промах, модель становится гораздо более склонной к следующему, ведь каждый новый токен генерируется на основе предыдущих.
Представьте, вы спрашиваете у модели: «Какая столица Франции?». И она по какой-то причине отвечает: «Берлин». С этого момента модель переключается в «режим Берлина» и начинает галлюцинировать в этом направлении, доходя до утверждений вроде «Бранденбургские ворота — культовый французский памятник».
Но если вы откроете новый чат с той же моделью и спросите: «Бранденбургские ворота находятся во Франции?», она почти наверняка ответит «Нет». В математике от перемены мест множителей произведение не меняется, но в мире промпт-инжиниринга этот закон не работает. Контекст решает всё.
Главный урок? Задавая вопросы по-разному, вы можете получить от модели совершенно противоположные ответы.
Именно поэтому, помимо технологий предотвращения ошибок, критически важно уделять внимание качеству ваших запросов (промптов). Будьте предельно точны, детальны и с самого начала знайте, чего вы хотите от модели. Это поможет направить её в нужное русло. В противном случае, рано или поздно её ответы начнут «краснеть» от ошибок.
На пути к победе над главным недостатком ИИ
Это прекрасное исследование даёт нам сразу несколько ключевых выводов:
- Оно показывает, как на самом деле работают модели, доказывая, что они кодируют степень неуверенности в собственных прогнозах.
- Оно абсолютно практично. Подобные детекторы можно встраивать в реальные ИИ-продукты, помогая бороться с главной «болезнью» генеративных систем.
- Оно доказывает, что промптинг имеет огромное значение. В зависимости от того, под каким углом вы задаёте вопрос, вы можете получить либо абсолютно верный, либо совершенно неверный ответ.
Более того, эта работа может стать основой для целого поколения стартапов, которые будут улучшать ИИ-продукты, анализируя внутренние мыслительные процессы моделей ещё до того, как те произнесут первое слово.
Но главный итог для нас с вами — это новое, более глубокое понимание галлюцинаций. Теперь вы знаете, что это такое, как с ними бороться, и, я надеюсь, начнёте ценить сложность этих моделей, которые делают нечто гораздо большее, чем «просто предсказывают следующее слово».
***✨ А что думаете вы? ✨
Делитесь мыслями в комментариях — ваше мнение вдохновляет нас и других!
Следите за новыми идеями и присоединяйтесь:
• Наш сайт — всё самое важное в одном месте
• Дзен — свежие статьи каждый день
• Телеграм — быстрые обновления и анонсы
• ВКонтакте — будьте в центре обсуждений
• Одноклассники — делитесь с близкими
Ваш отклик помогает нам создавать больше полезного контента. Спасибо, что вы с нами — давайте расти вместе! 🙌